ABtest一个总的目的和意图是,判断哪种种UI或rerank策略更优,通过事实的依据( CTR或下单率)判断哪种策略更符合用户的习惯和需求。
一、需求驱使
我们经常会面临多个设计方案的选择,比如app或pc端某个界面的某个按钮是用红色还是用蓝色,是放左边还是放右边。传统的解决方法通常是集体讨论表决,或者由某位专
家或领导或文青来拍板,实在决定不了时也有随机选一个上线的。虽然传统解决办法多数情况下也是有效的,但A/B 测试(A/B Testing)可能是解决这类问题的一个更好的方法。
所谓 A/B 测试,简单来说,就是为同一个目标制定两个方案(比如两个页面),让一部分用户使用 A 方案,另一部分用户使用 B 方案,记录下用户的使用情况,看哪个方案更符
合设计目标。
下面看一个例子:
在展示“格林秀上午酒店”这个poi时有客户端两种UI:
方案A:如左图,评分展示星状图片,消费人数再右边;
方案B:如右图,只展示评分分数,后边添加消费人数;
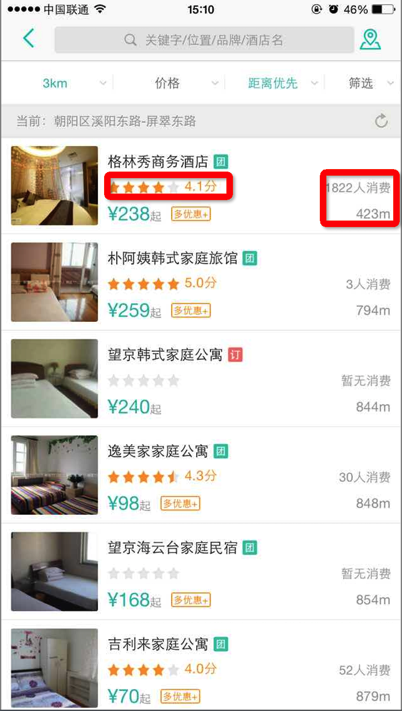
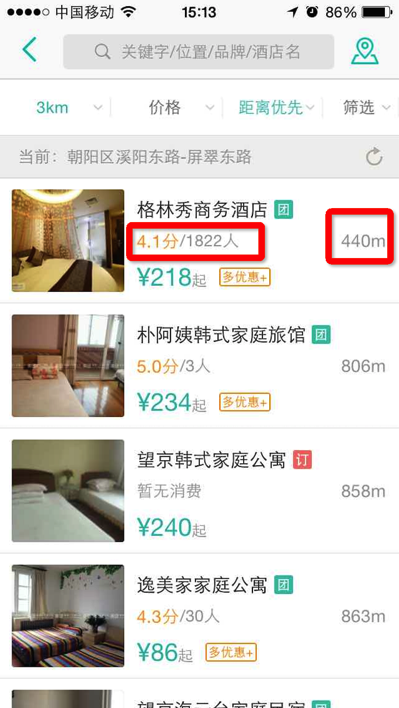
我们很难知道那种方案比较好,那我们可以做个实验,把a和B方案同时放到线上的生产环境,让一部分用户使用 A 方案,另一部分用户使用 B 方案,记录下用户的使用报表如下图,通过大自然的优胜劣汰法则,我们可以通过CTR或下单率等指标看哪个方案更符合设计目标。
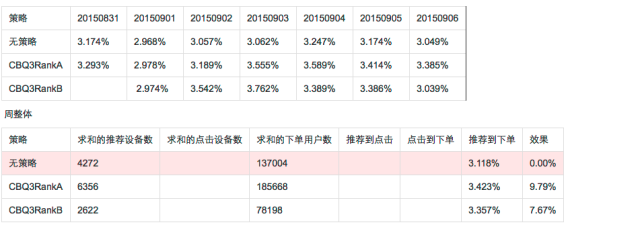
二、系统模型
abtest实验可以分成两种,客户端client实验和服务端server实验,客户端实验一般来说只是UI上的实验,比如上面的例子,纯粹是展示端的策略;而服务端的实验是返回给client数据的内容做实验,比如推荐的策略,订单列表rerank策略等。下面通过client和服务端的实验分别做介绍。
(1)客户端实验:
方案1:
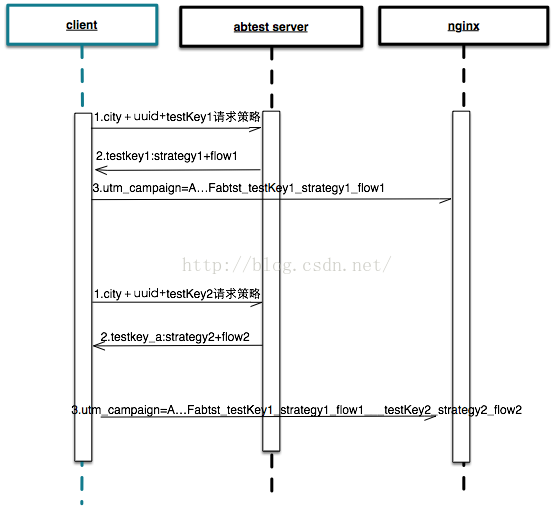
ABTest业务流程描述:
(1)客户端在需要获取ABTest策略的地方,通过RPC接口获取uuid在ABTest1这个实验下的规则:
- {
- “data”: [
- {
- “name”: “test1”,//实验key
- “strategy”: “strategy1”, //策略key,客户端根据策略key选择策略方案
- “flow”: “flow1”, //流量组,用于上报。每个流量组只属于一个策略。
- “finished”: false //标识实验是否终止,如果已经终止,则不再向utm_compaign参数的F字段append该规则,但是不影响规则,原规则依然生效。
- }
- ]
- }
其中testkey参数可以是多个ABTest实验的key:abtest1,abtest2。
(2)之后客户端向server发起的全部请求,URL的utm_compaign参数中的F位添加字符串:Fabtest1__strategy1__flow1,Nginx将utm_compaign打印到access日志。
(3)客户端在另一个需要获取ABTest策略的地方,通过http接口/get/abtest/{testkey}/{uuid} 获取uuid在ABTest2这个实验下的规则:
- {
- “data”: [
- {
- “name”: “abtest2”,//实验key,
- “strategy”: “strategy2”, //策略key,客户端根据策略key选择策略方案
- “flow”: “flow2”, //流量组,用于上报。每个流量组只属于一个策略。
- “finished”: false //标识实验是否终止,如果已经终止,则不再向utm_compaign参数的F字段append该规则,但是不影响规则,原规则依然生效。
- }
- ]
- }
(4)之后客户端向server发起的全部请求,URL的utm_compaign参数中的F位添加字符串:Fabtest1_strategy1__flow1___abtest2__strategy2__flow2,实验&策略&流量组采用两个下划线分隔,多个实验间采用三个下划线分隔。
(5)Nginx将URL中的utm_compaign打印到access日志,flume收集Nginx access 日志,同步到Hadoop,最后导入Hive。
(6)PM在报表系统,通过规则维度查询点击、转化报表。
这样导致的问题是url中utm_compaign的F字段过长,当实验到达一定数量的时候会出现,url过长,抓包会发现。实际上,客户端只关心我在某个界面中这次请求(uuid+ci+platform)命中的实验及策略,连utm_campaign都懒得拼接。
如URL中有utm_campaign=Fab_homepagewebview0717__b__d___ab_b_food_57_purepoilist_extinfo__a__a___ab_b_selectlist_paidui__a__leftflow___ab_i550poi_ktv__d__leftflow___ab_i_5_9_travelpoidetail__b__a___ab_i550poi_xxyl__d__d___ab_mingdiangexinghua0707__j__j___ab_waimaiwending__b__b___ab_b_travelsearchhot__a__a___ab_ifoodadvert__b__b___ab_pindaoqugexinghua0708__e__e___ab_itriphotpoi__b__leftflow___ab_i_6_0_webview__a__a___ab_b_travelpoilistrank__b__b2___ab_i_group_5_7_search_chunpoi__b__b1___ab_i_group_5_8_spdy__b__b___ab_ihotelqianzhi__b__b___i_group_5_2_deallist_poitype__d__d___ab_i550poi_shfw__d__leftflow___ab_ihotelpoilist__b__b___ab_itravelsearch0814__b__leftflow___ab_i_group_6_0_search_hotword__b__leftflow___ab_sieve_multiple_staticscore__base__base___ab_h_hotel_search_hot__b__b___ab_i_group_5_9_onsite__a__leftflow___ab_i_group_pingjiapush__a__a___ab_b_catesearchreplace__b__b___ab_b_deal_sieve_migrate__b__b___ab_i_group_travelhomepage0630__a__a___ab_i550poi_lr__d__leftflow___ab_b_searchmaiton__c__c___ab_groupcontext__a__a___ab_maidan_distance_first__smartfirst__smartfirst___ab_i_group_5_9notificationtest__a__a___ab_dealzhanshi__a__a1___ab_i_group_5_8_dns__a__leftflow___ab_ihotelbkdetail__a__a___ab_v1_po1_sieve_migrate__search__search
基于这个痛点,我们采用另一种上报方式;
方案二
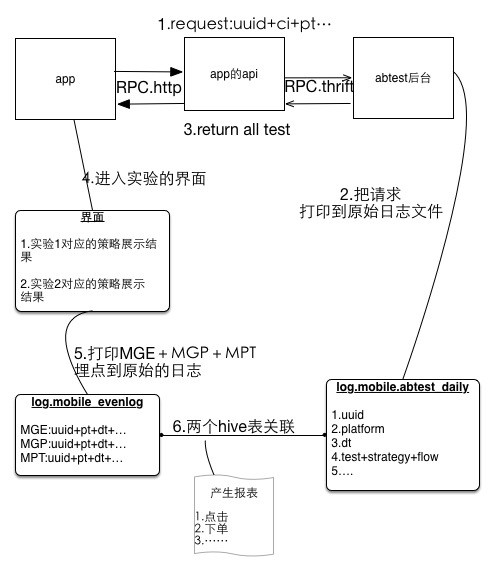
流程:
- (1)(客户端的工作):app启动或切换城市,会请求abtest服务后台,获得所有的实验的以及命中的策略缓存在app中。
- (2)(abtest后台的工作):abtest接收一个uuid+ci+pt的请求,返回给app所有的实验的以及命中的策略,同时将这次请求和结果通过flume_agent收集日志,同步到Hadoop,最后导入Hive。
- (3)(客户端的工作):在第1步的请求中的获得的所有的实验的以及命中的策略缓存在app中。
- (4)(客户端的工作) : 进入到一个做ab实验的界面,按照第3步命中的实验的策略+展示的业务数据处理展示逻辑。
- (5)(客户端的工作:):会把第4步这个界面的信息和埋点信息上传到数据中心的原始日志,异步步少重试的方式上报埋点,
按HTTP GET/POST 日志收集方式,MGE,MGP,MPT的信息定义可以。移动页面流跟踪事件,这些事件封装为MPT事件,具体格式如下:
<pre name=”code” class=“javascript”>“nm”:”MPT”,//页面流跟踪事件(PageTrack)
“val”:{
“root”: //层级前缀
“name”: //页面名/组件名/弹窗名
“content”: //数据请求URL内容/弹窗内容
“type”: //page/alert
}
“nm”:”MGE”,//Event跟踪,需要客户端手工埋点,用于解决临时统计需求
“val”:{
“cid”: //页面名 类别 category id
“act”: //动作名 动作 action
“lab”: //动作描述 注释 label
“val”: //页面描述 权值 value
}
“nm”:”MGP”,//页面跟踪,需要客户端手工埋点,用于解决临时统计需求
“val”:{
“root”: //层级前缀(非必需)
“name”: //页面名/组件名/弹窗名(必须)
“content”: //数据请求URL内容/弹窗内容(必须)
“type”: //page/alert
}
(6)(数据组的工作):应用系统可以通过flume,将原始日志同步到Hadoop,最后导入Hive表,通过关联的条件将两个hive表关联,同时关联一些点击下单等数据,清洗数据成报表。
方案一和方案二的比较:
(1)方案一的缺点是会添加客户端RD的URL拼接工作,致命的是实验到达一定个数,访问页面过深URL过长导致被截断(sa控制http的url的长度和header大小)
(2)方案一的有点是,数据组RD清洗数据比较方便,只需收集ngixn日志,对url进行清洗即可产生报表,只需要关联点单点击等报表。
(3)方案二的优点是,通过各自打埋点成原始日志到hadoop平台方式,客户端只关心自己命中的策略以及处理的业务逻辑,与业务无关的事情切入较少。
(4)方案二的缺点是,客户打的埋点需要跟abtest后台的表进行关联,关联的逻辑不固定,添加了清洗数据的复杂度。
最后基于系统长期的发展,采取了方案二,前期使用的方案一将在app的新版本中废弃。
(2)服务端实验:

其实服务端的实验跟客户端的实验的是类似的,只需要添加额外的工作:在服务端请求abtest后台,需要知道本次请求以及实验命中的策略,并将结果返回给客户端。

